
3月16日,,李彥宏站在舞臺聚光燈下,,感受著全球科技從業(yè)者目光的注視,,風(fēng)頭一時無兩,。
3年前,,同一個場景,,他也曾這么出風(fēng)頭過,但當(dāng)時是因為一瓶從頭澆下的礦泉水,。
這一次他顯然信心十足,。預(yù)熱了幾個月,只要“文心一言”一發(fā)布,,在ChatGPT掀起全球AIGC(生成式AI)狂潮乃至狂熱的當(dāng)下,,百度就將成為全球第2個觸摸到未來的科技先鋒。
沒想到,,發(fā)布當(dāng)天,,李彥宏在臺上說,百度股價在板上跌,。
無論是發(fā)布會前一天OpenAI不講武德地推出了革新的GPT-4模型,,還是發(fā)布會上缺少實機演示,亦或是第一批嘗鮮的用戶輸入“愛國”結(jié)果畫出星條旗,,都沉重打擊了市場信心,。
發(fā)布會開始不到20分鐘,百度港股股價就暴跌超9.8%,,后來股價略有上升,,但跌幅仍超5%。不出意料,,微博,、知乎迅速出現(xiàn)了一片嘲笑聲,“百度股價跳水”被送上熱搜,,線上線下彌漫著快活的空氣。
然而,,僅過了一晚上,,股市完全變了。3月17日港股開盤后,,百度幾乎是直線拉升,,日內(nèi)繼續(xù)波動上漲,全天漲幅近15%,。隨后幾天,,余威未消,百度股價繼續(xù)上漲,,目前已經(jīng)回到年內(nèi)高位,。
事實上,,業(yè)界很快回味過來了。
文心一言雖然比GPT4差得遠,,甚至比不上GPT3.5的ChatGPT,,但依然是能用的。各種讓人啼笑皆非的產(chǎn)出結(jié)果恰恰證實了技術(shù)的真實性,,沒有弄虛作假,,這就夠了。只要是真的,,花錢花時間,,總能迭代到好用的時候。
況且要論落后,,落后第1名,,那也是行業(yè)第2,在一個公認前途無量的領(lǐng)域做到世界第2,,不強么?
風(fēng)向一下子變了,,這下壓力來到了其他互聯(lián)網(wǎng)大廠一邊:
一直被嘲諷“掉隊”的百度做出來了文心一言,你們在干什么?
1,、第四波浪潮?
不能完全怪其他大廠不努力,,從歷史來看,過去AI發(fā)展經(jīng)歷了3波高潮,,但總體來看,,雷聲大,雨點小,。
人工智能概念的提出始于1956年的美國達特茅斯會議,,1959年Arthur Samuel提出了機器學(xué)習(xí),推動人工智能進入第一個發(fā)展高潮期,,但因為對現(xiàn)實問題束手無策而衰退,。這個階段,AI只會依據(jù)規(guī)則證明中學(xué)數(shù)學(xué)定理,。
此后70年代末期出現(xiàn)了專家系統(tǒng),,標志著人工智能從理論研究走向?qū)嶋H應(yīng)用。80年代到90年代隨著美國和日本立項支持人工智能研究,,人工智能進入第二個發(fā)展高潮期,,期間人工智能相關(guān)的數(shù)學(xué)模型取得了一系列重大突破,如著名的多層神經(jīng)網(wǎng)絡(luò),、BP反向傳播算法等,,算法模型準確度和專家系統(tǒng)進一步提升。
然而在這個階段,AI的能力上限也只是下贏國際象棋,。
新世紀以來,,互聯(lián)網(wǎng)將人類代入大數(shù)據(jù)時代,深度學(xué)習(xí)算法的出現(xiàn)和強化,,GPU,、NPU、FPGA等芯片技術(shù)帶來的算力突破,,共同推動了AI第三次浪潮的出現(xiàn),。
2018年,新的里程碑出現(xiàn),。
谷歌推出大規(guī)模預(yù)訓(xùn)練語言模型BERT,,通過3億參數(shù)量的訓(xùn)練,在機器閱讀理解頂級水平測試SQuAD1.1的2個衡量指標上全面超越人類,,并在11種不同的NLP測試中達到SOTA(業(yè)內(nèi)最佳)表現(xiàn),,宣布了大模型時代的到來。
次年,,OpenAI迅速跟進,,將GPT-1的1.17億參數(shù)量迭代至GPT-2的15億,在沒有對模型結(jié)構(gòu)做出過多創(chuàng)新的情況下,,實現(xiàn)了超強的內(nèi)容生成能力,。
又過了1年,現(xiàn)在已經(jīng)家喻戶曉的GPT-3誕生,,大模型參數(shù)量暴漲到1750億,,系統(tǒng)出現(xiàn)了從量變到質(zhì)變的跨越。在優(yōu)化和熟識1年多后,,OpenAI將基于GPT-3.5的ChatGPT推向市場,,轟動了全世界。

推出短短5天內(nèi)注冊用戶量就超過100萬,,2個月后突破1個億,,平均每天1300萬獨立訪客使用,ChatGPT不僅自己打破記錄,,還掀起了一波全球性狂潮,。
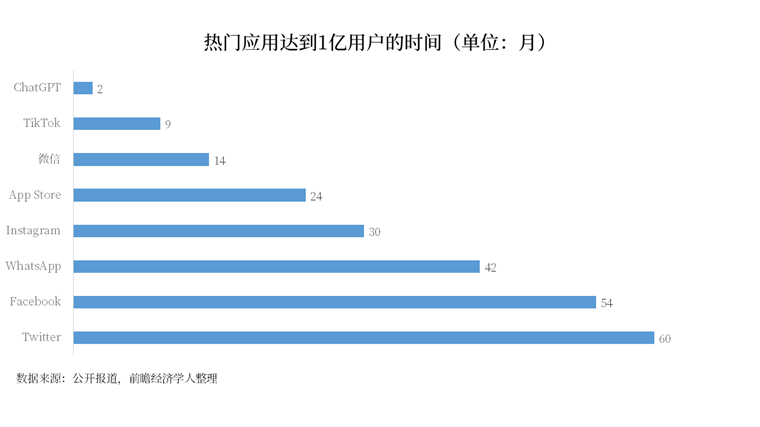
在同行還沒反應(yīng)過來的時候,OpenAI又以迅雷不及掩耳之勢推出了GPT-4,。雖然沒有公布詳細參數(shù),但其實際使用體驗的巨大提升,,再次震動了行業(yè),。
在智能化水平上,GPT-4和之前的模型產(chǎn)生了天壤之別。比如說,,在美國大學(xué)先修課程微積分BC考試中,,GPT-4獲得4分(滿分5分),而GPT-3獲得1分,。GPT-3.5是GPT-3和GPT-4的中間模型,,也獲得4分。
模擬律師考試方面,,GPT-4以排名前10%的成績通過,,GPT-3.5的分數(shù)徘徊在后10%左右。
GPT-4在各種專業(yè)和學(xué)術(shù)基準上的表現(xiàn),,已經(jīng)達到了“人類水平”,。
GPT-4更有趣的方面之一是多模態(tài)。與GPT-3和GPT-3.5只能接受文本提示不同,,GPT-4還能接受圖像提示來執(zhí)行某些操作,,也就是輸入圖片,它生成一段相關(guān)的文字內(nèi)容,。
而這,,很可能還不是OpenAI的全部招式。
從時間上看,,GPT-4早在2022年年中就基本完成;從產(chǎn)品上看,,OpenAI還有很多,比如其中一款DELL-E2,,可以輸入文字來一張圖片,,正好和GPT-4互補。
很難想象,,OpenAI到底領(lǐng)先對手幾個身位?
作為行業(yè)第2,,百度在2019年就已開始積累AI預(yù)訓(xùn)練模型技術(shù),2021年12月正式發(fā)布了全球首個知識增強千億大模型鵬城-百度·文心,,參數(shù)規(guī)模達到2600億,,比ChatGPT還大。
有人可能會嘲笑,,怎么用更大的模型,,百度的產(chǎn)品還不如別人。
這里要為百度說句話,,模型的參數(shù)量不是決定最終產(chǎn)品的唯一因素,,模型的架構(gòu)設(shè)計、數(shù)據(jù)質(zhì)量,、訓(xùn)練策略等因素都會影響模型的能力和性能,。
就拿數(shù)據(jù)質(zhì)量來說,,如果百度是用中文互聯(lián)網(wǎng)的信息來訓(xùn)練,那必然能起到一種事倍功半的效果,。
3月,,谷歌正式開放類ChatGPT產(chǎn)品Bard的訪問,成為全球第3,,其背后的LaMDA模型使用多達1370億個參數(shù)進行訓(xùn)練,。而從實際使用來看,這個第3當(dāng)之無愧——有時候連文心一言都不如,。
當(dāng)然,,這還是比一眾連產(chǎn)品都沒有的廠商要好得多。
2,、卷起來了
中國率先做出類ChatGPT產(chǎn)品的為什么不是騰訊,、阿里、字節(jié)跳動這樣頂尖的互聯(lián)網(wǎng)大廠,,而是百度這種“掉隊”廠商?
這里引用周鴻祎近期采訪時的一段話:
“國內(nèi)互聯(lián)網(wǎng)公司花錢多少不一樣,,聚集人工智能的人才團隊大小不一樣,但是思路一樣——人工智能應(yīng)該找場景,,要解決自己業(yè)務(wù)中遇到的問題,。
所以,為什么中國的人工智能都用來解決人臉識別,、圖像濾鏡做得更漂亮,,如果一個人工智能技術(shù)和自己的業(yè)務(wù)不能結(jié)合,可能就會認為沒太大意義,。
所以,,沒有人想到用GPT NLP的模型解決通用知識理解和推理的問題,更沒有人想到大算力大數(shù)據(jù),,最后做出一個大模型,,能夠產(chǎn)生一種連OpenAI自己都想不到的智能化的結(jié)果�,!�
總結(jié)一下,,就是短期看不到變現(xiàn)可能的,就不做,。
這段話不一定全對,,但一定有正確的地方,因為確實有大廠身體力行地證明了這一點,。
比如騰訊,。
ChatGPT火了之后,騰訊深藏于血脈之中的本能立刻覺醒,,馬上宣布成立“混元助手(HunyuanAide)”項目組,。
從人員構(gòu)成來看,,騰訊這回是下了血本了。
根據(jù)36氪“職場Bonus”消息,,項目組Owner張正友是騰訊史上最高專業(yè)職級擁有者,首位17級研究員/杰出科學(xué)家;下面的3位PM,,分別是騰訊在AI算法,、AI工程和商業(yè)化方面的高管;7位組長是來自內(nèi)部多個團隊的骨干;支持人員更是覆蓋廣泛,連微信和互娛的也出現(xiàn)在名單人員的業(yè)務(wù)覆蓋面內(nèi),,可見騰訊之重視,。
不過之前可不是這樣的。
事實上,,如果搜索關(guān)鍵詞可以發(fā)現(xiàn),,“混元”這個名字并不是第一次出現(xiàn)在騰訊的項目中。
早在去年4月,,騰訊就宣布了發(fā)布多模態(tài)“混元”AI大模型的消息,,不過這個模型當(dāng)時并沒有用在類ChatGPT產(chǎn)品上。
用在哪里了呢?當(dāng)然是能直接看到錢的地方啊,。
根據(jù)當(dāng)時的通稿,,“混元”大模型“被廣泛應(yīng)用到廣告創(chuàng)作、廣告檢索,、廣告推薦等騰訊業(yè)務(wù)場景中”,。具體來說,就是利用AI更好地理解廣告內(nèi)容,,然后更加精確地推送到你手機上,。
只能說,不愧是你啊,。
除了騰訊之外,,國內(nèi)還有幾個趕晚集的大廠。
首先是阿里,。2020年,,阿里達摩院和清華大學(xué)共同推出了3億參數(shù)量的M6大模型,2021年1月模型參數(shù)規(guī)模到達百億;2021年5月,,具有萬億參數(shù)規(guī)模的模型正式投入使用,。
2022年10月,M6的參數(shù)規(guī)模擴展到驚人的10萬億,,成為全球最大的AI預(yù)訓(xùn)練模型,。
在產(chǎn)品方面,和騰訊一樣,,M6主要應(yīng)用在阿里業(yè)務(wù)上,,比如增進淘寶,、支付寶等平臺的搜索及內(nèi)容認知精度等。去年阿里曾公布其在AIGC方面的成果,,生成的實景圖片已經(jīng)十分逼真,。
今年2月,據(jù)媒體報道,,阿里版聊天機器人ChatGPT正在研發(fā)中,,目前處于內(nèi)測階段。
之后是京東,。2月10日,,京東云旗下言犀人工智能應(yīng)用平臺宣布將整合過往產(chǎn)業(yè)實踐和技術(shù)積累,推出產(chǎn)業(yè)版ChatGPT:ChatJD,。
不過這個產(chǎn)品也許八字還沒一撇,,其通稿公布的信息中,參數(shù)量用的是“預(yù)計”為千億級別的字眼,。
在此前的采訪中,,京東方面曾透露過自研領(lǐng)域知識大模型K-PLUG的消息,稱其生成的商品文案覆蓋了京東3000+品類,,累計生成30億字,,帶來超過3億元GMV。
就算新產(chǎn)品發(fā)布了,,也和普通網(wǎng)友沒什么關(guān)系,,因為其定位的領(lǐng)域是零售和金融,服務(wù)于京東相關(guān)領(lǐng)域,。
字節(jié)跳動方面發(fā)力較晚,。據(jù)公開報道,到今年2月,,ChatGPT已經(jīng)火遍半邊天了,,字節(jié)還只是“正在大模型方面布局”。知情人士表示,,字節(jié)跳動語言大模型團隊在今年組建,,探索方向主要為與搜索、廣告等下游業(yè)務(wù)的結(jié)合,,語言大模型團隊的預(yù)期是在今年年中推出大模型,。
另外還有華為。2021年4月,,華為發(fā)布了盤古大模型,,包括30億參數(shù)的視覺(CV)預(yù)訓(xùn)練模型,以及與循環(huán)智能,、鵬城實驗室聯(lián)合開發(fā)的千億參數(shù),、40TB訓(xùn)練數(shù)據(jù)的中文語言(NLP)預(yù)訓(xùn)練模型,。
不過無論是從當(dāng)時公布的布局,后續(xù)通稿,,還是近期的回應(yīng)來看,,華為似乎都沒有推出類似ChatGPT這樣面對普通網(wǎng)民的通用應(yīng)用的意愿。也許未來我們可以在鴻蒙的車機上體驗到華為的技術(shù)實力,。
還有部分大廠,,沒有公布模型方面的信息,專攻應(yīng)用層面,。
比如網(wǎng)易有道方面稱,未來或?qū)⑼瞥鯟hatGPT同源技術(shù)產(chǎn)品,,應(yīng)用場景圍繞在線教育,。
三六零在互動平臺上表示,正計劃盡快推出類ChatGPT技術(shù)的demo(試用版本)應(yīng)用,。
科大訊飛2月在投資者互動平臺回應(yīng)稱,,公司在該方向技術(shù)和應(yīng)用具備長期深厚的積累�,?拼笥嶏wAI學(xué)習(xí)機將成為該項技術(shù)率先落地的產(chǎn)品,,將于今年5月6日進行產(chǎn)品級發(fā)布。
有意思的是,,去年12月,,他們的董秘還說“目前沒有類似ChatGPT的產(chǎn)品計劃”。
3,、勝負未分
必須強調(diào)的是,,雖然行業(yè)的領(lǐng)先者已經(jīng)出現(xiàn),但是長期來看,,生成式AI其實還在萌芽階段,,未來競爭格局依然可能生變。
Gartner《2022年人工智能技術(shù)成熟度曲線》報告預(yù)測,,廣闊的應(yīng)用場景和需求空間吸引大量資本和技術(shù)投入,,預(yù)計將在2-5年內(nèi)實現(xiàn)規(guī)模化應(yīng)用,。

根據(jù)Precedence Research,,生成式AI將在2022年后迎來應(yīng)用的爆發(fā),市場空間預(yù)計由2022年的108億美元上漲至2032年的1181億美元,,未來10年的CAGR高達27%,。

在細分領(lǐng)域,目前生成式AI還主要應(yīng)用在媒體與娛樂上,,市場份額占比34%,。
不過在此以后,,商業(yè)和金融服務(wù)部門預(yù)計將以最快的速度增長 36.4%,該行業(yè)的市場擴張歸因于人工智能 (AI) 在行業(yè)中越來越多地使用,,以阻止欺詐,、保護數(shù)據(jù)并滿足金融服務(wù)中各利益相關(guān)者不斷變化的需求。
總而言之,,這個行業(yè)才剛剛起步,,機會很多,不確定性也很大,。
但有一點可以確定,,之前國內(nèi)大廠的功利主義和商業(yè)KPI導(dǎo)向在此刻將會得到教育,接下來可以預(yù)期,,行業(yè)對AI成果商業(yè)化的預(yù)期會更加寬容和長期主義,,對于AI生產(chǎn)力和增長曲線的認知也會更加清晰和堅定。
前瞻網(wǎng)
賣V導(dǎo)軌V絲桿 發(fā)表于 2023-3-27 17:10
這不是很悲哀的一件事情嗎,?差距大怕笑話不做 然后差距越來越大,國內(nèi)網(wǎng)友也確實對國內(nèi)公司包容性不夠,, ...
山野向南cj 發(fā)表于 2023-3-28 11:26
體驗一下文心一言
鑄林邀風(fēng) 發(fā)表于 2023-3-30 17:55
現(xiàn)在個人也能使用了嗎

| 歡迎光臨 機械社區(qū) (http://97307.cn/) | Powered by Discuz! X3.4 |